Python 读/写Excel文件
Python与Excel交互——Xlwings
基础
引入库
import xlwings as xw
打开 Excel 程序,默认设置:程序可见,只打开不新建工作薄
app = xw.App(visible=True,add_book=False)
#新建工作簿 (如果不接下一条代码的话,Excel只会一闪而过,卖个萌就走了)
wb = app.books.add()
打开已有工作簿(支持绝对路径和相对路径)
# 打开一个新的 workbook
wb = xw.Book()
# 打开当前目录已经存在的一个 workbook
wb = xw.Book('example.xlsx')
#这样的话就不会频繁打开新的Excel
保存工作簿
wb.save('example.xlsx')
退出工作簿(可省略)
wb.close()
退出Excel
app.quit()
引用Excel工作表,单元格
- 引用工作表
sht = wb.sheets[0]
#sht = wb.sheets[第一个sheet名]
- 引用单元格
rng = sht.range('a1')
#rng = sht['a1']
#rng = sht[0,0] 第一行的第一列即a1,相当于pandas的切片
- 引用区域
rng = sht.range('a1:a5')
#rng = sht['a1:a5']
#rng = sht[:5,0]
写入数据
(xlwings多个单元格的写入大多是以表格形式)
选择起始单元格A1,写入字符串‘Hello’
sht.range('a1').value = 'Hello'
一维数据
默认按行插入:A1:D1分别写入1,2,3,4
sht.range('a1').value = [1,2,3,4]
等同于
sht.range('a1:d1').value = [1,2,3,4]
按列插入: A2:A5分别写入5,6,7,8
sht.range('a2').options(transpose=True).value = [5,6,7,8]
既然默认的是按行写入,我们就把它倒过来嘛(transpose),单词要打对,如果你打错单词,它不会报错,而会按默认的行来写入
二维数据
多行输入就要用二维列表了:
sht.range('a6').expand('table').value =
[['a','b','c'],['d','e','f'],['g','h','i']]
Excel中区域的选取表格
# 选取第一列
rng=sht. range('A1').expand('down')
rng.value=['a1','a2','a3']

# 选取第一行
rng=sht.range('A1').expand('right')
rng=['a1','b1']

# 选取表格
rng.sht.range('A1').expand('table')
rng.value=[[‘a1’,'a2','a3'],['b1','b2','b3']]

读取数据
读取A1:D4(直接填入单元格范围就行了)
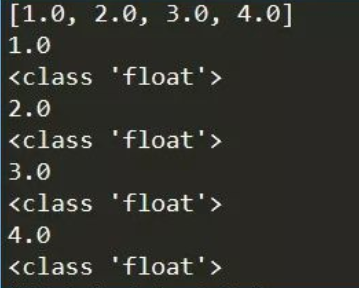
print(sht.range('a1:d4').value)
返回的值是列表形式,多行多列为二维列表,但有一点要注意,返回的数值默认是浮点数
a = sht.range('a1:d1').value
print(a)
for i in a:
print(i)
print(type(i))
读取excel的第一列怎么做?
*a = sht.range('a:a').value
print(len(a))
你将会得到一个1048576个元素的列表,也就是空值也包含进去了,所以这种方法不行
思路:先计算单元格的行数(前提是连续的单元格)
rng = sht.range('a1').expand('table')
nrows = rng.rows.count
接着就可以按准确范围读取了
a = sht.range(f'a1:a{nrows}').value
同理选取一行的数据也一样
ncols = rng.columns.count
#用切片
fst_col = sht[0,:ncols].value
range常用的api
# 引用当前活动工作表的单元格
rng=xw.Range('A1')
# 加入超链接
# rng.add_hyperlink(r'www.baidu.com','百度',‘提示:点击即链接到百度')
# 取得当前range的地址
rng.address
rng.get_address()
# 清除range的内容
rng.clear_contents()
# 清除格式和内容
rng.clear()
# 取得range的背景色,以元组形式返回RGB值
rng.color
# 设置range的颜色
rng.color=(255,255,255)
# 清除range的背景色
rng.color=None
# 获得range的第一列列标
rng.column
# 返回range中单元格的数据
rng.count
# 返回current_region
rng.current_region
# 返回ctrl + 方向
rng.end('down')
# 获取公式或者输入公式
rng.formula='=SUM(B1:B5)'
# 数组公式
rng.formula_array
# 获得单元格的绝对地址
rng.get_address(row_absolute=True, column_absolute=True,include_sheetname=False, external=False)
# 获得列宽
rng.column_width
# 返回range的总宽度
rng.width
# 获得range的超链接
rng.hyperlink
# 获得range中右下角最后一个单元格
rng.last_cell
# range平移
rng.offset(row_offset=0,column_offset=0)
#range进行resize改变range的大小
rng.resize(row_size=None,column_size=None)
# range的第一行行标
rng.row
# 行的高度,所有行一样高返回行高,不一样返回None
rng.row_height
# 返回range的总高度
rng.height
# 返回range的行数和列数
rng.shape
# 返回range所在的sheet
rng.sheet
#返回range的所有行
rng.rows
# range的第一行
rng.rows[0]
# range的总行数
rng.rows.count
# 返回range的所有列
rng.columns
# 返回range的第一列
rng.columns[0]
# 返回range的列数
rng.columns.count
# 所有range的大小自适应
rng.autofit()
# 所有列宽度自适应
rng.columns.autofit()
# 所有行宽度自适应
rng.rows.autofit()
books 工作簿集合的api
# 新建工作簿
xw.books.add()
# 引用当前活动工作簿
xw.books.active
sheets 工作表的集合
# 新建工作表
xw.sheets.add(name=None,before=None,after=None)
# 引用当前活动sheet
xw.sheets.active
练习
保存数据
import xlwings as xw
wb = xw.Book()
sht = wb.sheets[0]
info_list = [['20190001','已揽收','凯撒邮局'],
['20190001','已发货','凯撒邮局'],
['20192288','已揽收','麻花镇邮局'],
['20192288','已发货','麻花镇邮局'],
['20192288','正在派送','阿里山']]
首先,写入表头,
titles = [['包裹号','状态','地点']]
sht.range('a1').value = titles
然后写入轨迹信息
sht.range('a2').value = info_list
保存
wb.save('Track.xlsx')
这样,第一步保存数据就完成了
更新数据
second = [
['20190001','已揽收','凯撒邮局'],
['20190001','已发货','凯撒邮局'],
['20190001','正在派送','王村村口'],
['20190001','已签收','老王家'],
['20192288','已揽收','麻花镇邮局'],
['20192288','已发货','麻花镇邮局'],
['20192288','正在派送','阿里山'],
['20192288','已发货','小马家']
]
更新数据其实没什么难度,直接覆盖写入就好了
但是如果我想知道更新了多少条记录怎么办呢?
将数据去重,剩下的就是更新的
首先读取之前写入的信息:
import xlwings as xw
wb = xw.Book('Track.xlsx')
sht = wb.sheets[0]
first = sht.range('a2').expand('table').value
print(first)

乍一看没什么问题,仔细一看,包裹号都成了浮点数!写入的时候是字符串,读取出来就成了浮点数,所以这时候去重,由于数据类型不一致,无法真正去重。
思路一:直接转化数据类型,将每个列表的第一个元素转为整数,再转为字符串
first_str = []
for i in first:
print(round(i[0]))
i[0] = str(round(i[0]))
first_str.append(i)
print(first_str)
思路二:如果大家对Excel熟悉的话,就会知道,在数字前面加一个英文字符的单引号('),数字就变成文本格式了,所以我们可以在写入信息的时候加上一个单引号,这样Excel就不会乱改格式了。
import xlwings as xw
wb = xw.Book('Track.xlsx')
sht = wb.sheets[0]
info_list = [["'20190001","已揽收","凯撒邮局"],
["'20190001","已发货","凯撒邮局"],
["'20192288","已揽收","麻花镇邮局"],
["'20192288","已发货","麻花镇邮局"],
["'20192288","正在派送","阿里山"]]
sht.range('a2').value = info_list
values = sht.range('a2').expand('table').value
print(values)
然后开始真正的去重
extra = [i for i in second if i not in first_str]
print(extra)
print(len(extra))
结果没问题,多出三个轨迹信息

为了介绍xlwings的插入功能,我们再来设想这样一种情况:
已经有了两个包裹的轨迹情况
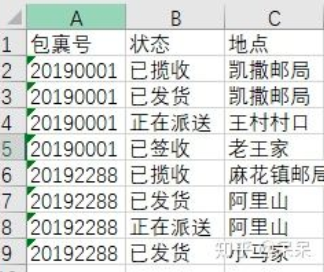
但是我们得到了20190001包裹的最新情况,需要更新这一个包裹的信息:
[
["20190001","已揽收","凯撒邮局"],
["20190001","已发货","凯撒邮局"],
["20190001","正在派送","王村村口"],
["20190001","已签收","老王家"]
]
首先,去重
extra = [i for i in second if i not in first_str]
print(extra)
显示要更新的就一条
读取第一列的包裹号
rng = sht.range('a1').expand('table')
nrows = rng.rows.count
row_a = sht.range(f'a1:a{nrows}').value
找到要更新的包裹号
for i in extra:
pkg = i[0]
position = row_a.index(pkg)
print(position)
times = row_a.count(pkg)
print(times)
position = 1 是指在第二行出现,times = 3 是指一共有3个此包裹号的信息
所以要在第五行插入
rows = position+times+1
sht.range(f'{rows}:{rows}').api.Insert()
然后再写入更新的信息
sht.range(f'a{rows}').value = extra
大功告成!保存
wb.save()
插入语句
sht.range('单元格或行列').api.Insert()
#插入列
sht.range('a:a').api.Insert()
#插入行
sht.range('2:2').api.Insert()
#插入单元格
sht.range('b4').api.Insert()